目录
题目
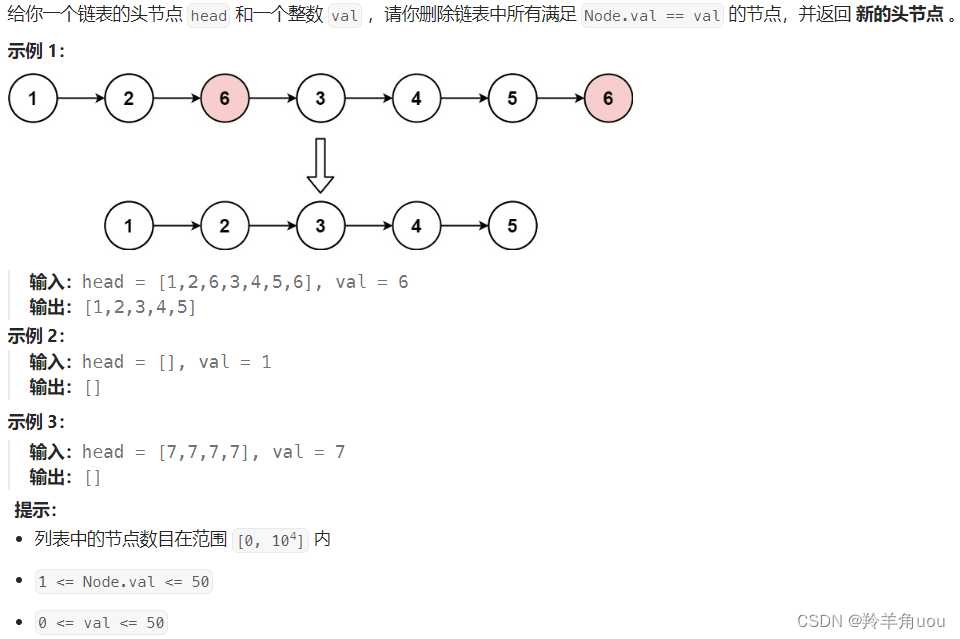
1.移除链表元素
2.反转链表
3.链表的中间节点
4.合并两个有序链表
5.环形链表的约瑟夫问题
解析
题目1:创建新链表
题目2:巧用三个指针
题目3:快慢指针
题目4:哨兵位节点
题目5:环形链表

介绍完了单链表,我们这次来说几个经典的题目,本篇的题目衔接下一章双向链表哦~
题目
1.移除链表元素
2.反转链表
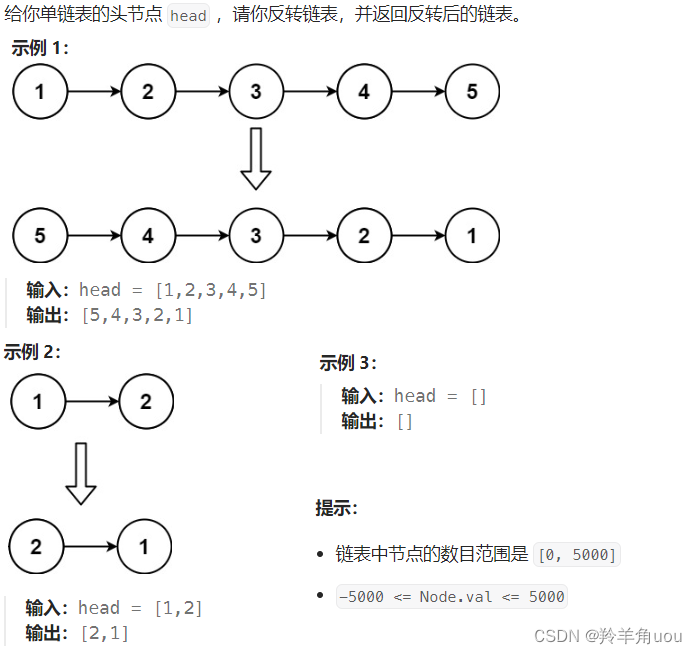

3.链表的中间节点
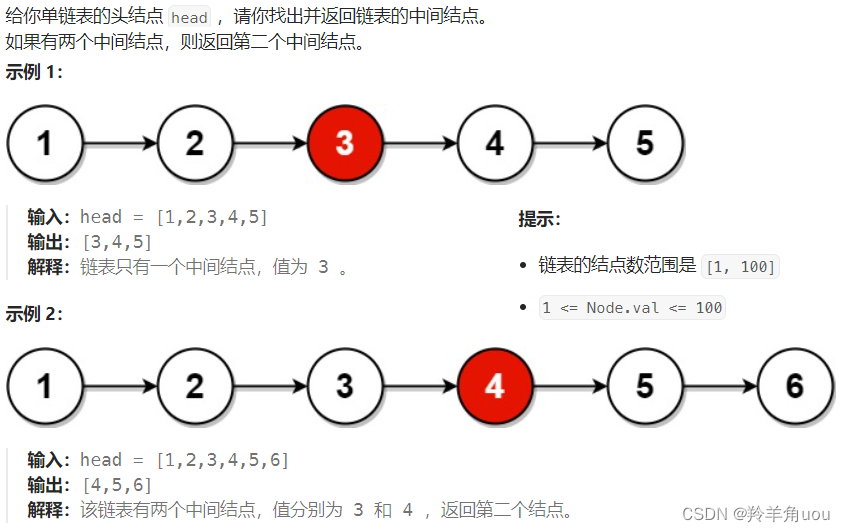
4.合并两个有序链表
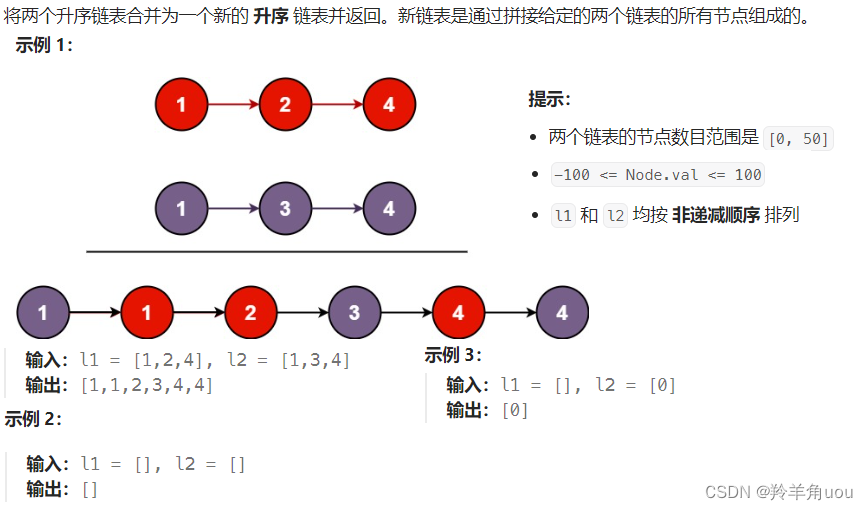
5.环形链表的约瑟夫问题


我们来看看本篇要介绍的解法吧
解析
这里介绍的解析仅供参考,算法题的实现思路是很多的,小编就不一一详细介绍了,我们主要介绍小编认为比较好的方法~
题目1:创建新链表
思路:找值不为val的节点,尾插到新链表中
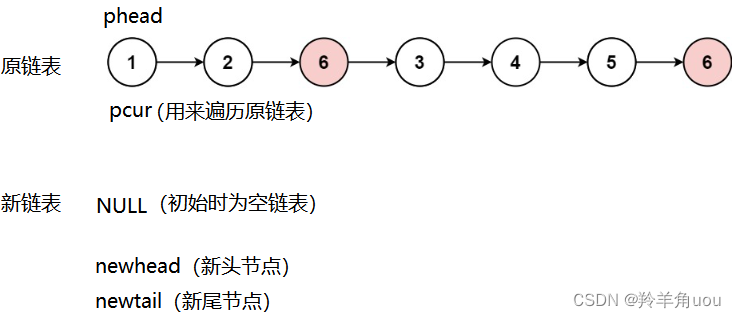
pcur不等于val时,就把节点放在新链表中,新链表初始为空链表,所以新链表的第一个节点既是newhead也是newtail,放好后pcur往后走,继续判断节点是否等于val
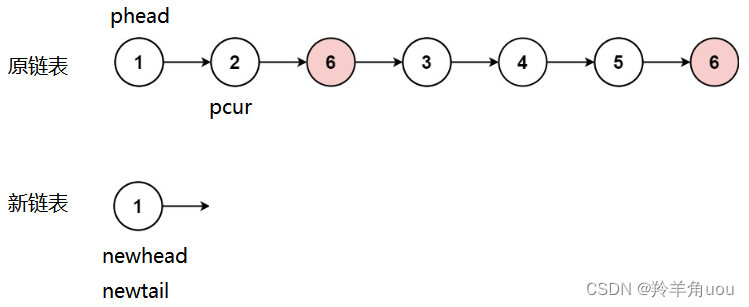
pcur所指向的节点不等于val,把这个节点尾插到新链表里面,newhead不变,newtail往后走,pcur也往后走,继续判断
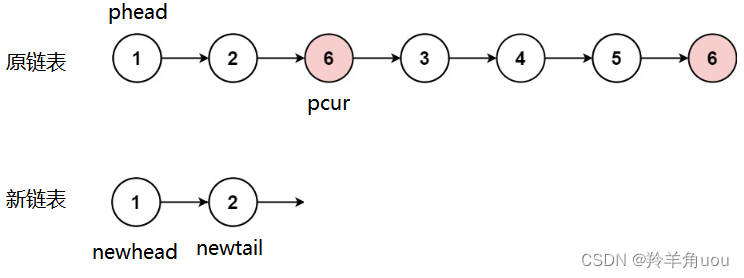
此时pcur指向的节点值为val,pcur再往后走,其余不变
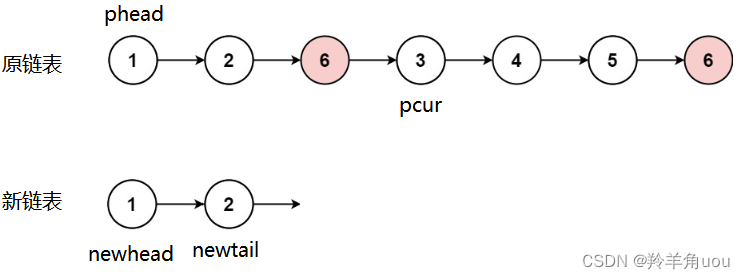
一直到pcur遍历完原链表,此时新链表就是去掉所有等于val值的节点的链表
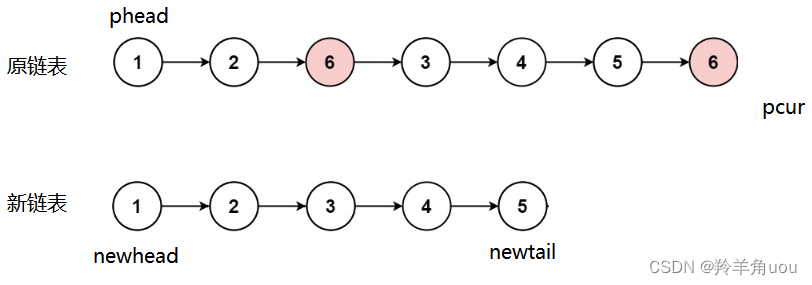
我们代码实现一下
首先把结构体类型 struct ListNode 换个名字,方便定义,就换成ListNode
typedef struct ListNode ListNode;然后在题目给的函数中进行实现
typedef struct ListNode ListNode;
struct ListNode* removeElements(struct ListNode* head, int val)
{
ListNode* newhead, * newtail;//定义新头节点、新尾节点
newhead = newtail = NULL;//新链表初始时为空
ListNode* pcur = head;//pcur初始时指向原链表首节点
while ()//开始遍历链表
{
}
}循环结束的条件应该是pcur不为NULL,循环体里面就是刚刚分析的过程
struct ListNode* removeElements(struct ListNode* head, int val)
{
ListNode* newhead, * newtail;//定义新头节点、新尾节点
newhead = newtail = NULL;//新链表初始时为空
ListNode* pcur = head;//pcur初始时指向原链表首节点
while (pcur)//开始遍历链表
{
if (pcur->val != val)//找pcur不为val的节点
{
if (newhead == NULL)//新链表为空
{
newhead = newtail = pcur;
}
else//新链表不为空
{
newtail->next = pcur;
newtail = newtail->next;
}
}
pcur = pcur->next;//继续往后遍历
}
if(newtail)
newtail->next = NULL;
return newhead;
}题目2:巧用三个指针
参考思路1:依旧是新创建一个链表,遍历原链表,将原链表中的节点采用头插的形式放在新链表中,就可以实现链表的翻转
参考思路2:创建3个指针,完成原链表的翻转
我们来实现思路2,这个思路一般不太好想
创建3个变量,n1、n2、n3初始时分别指向NULL、节点1、节点2
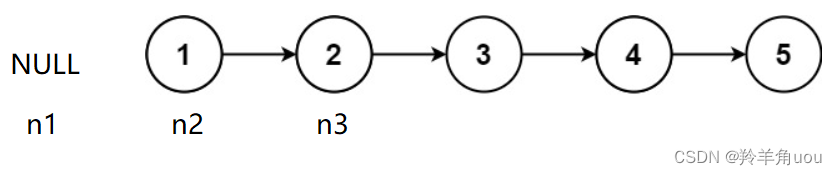
然后让n2指向n1,n1走到n2的位置,n2走到n3的位置,n3走向下一个节点
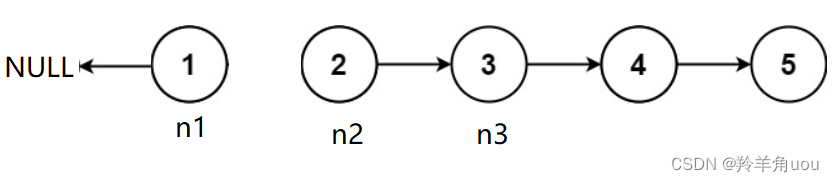
然后再重复上面的步骤,n2指向n1,n1走到n2的位置,n2走到n3的位置,n3走向下一个节点,

走到这里的时候n3就不能继续走了,n1和n2继续走
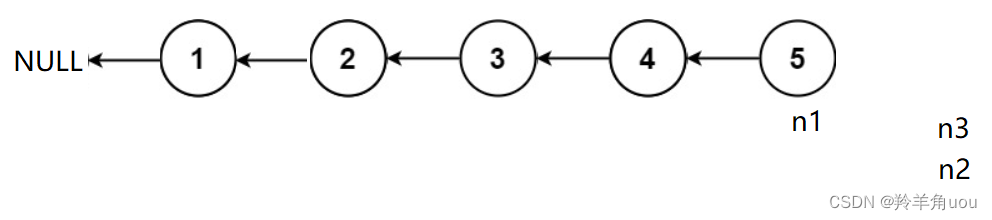
此时n1就是链表的新头节点
我们来代码实现,依旧是重命名一下,把结构体类型 struct ListNode 换个名字,方便定义,换成ListNode
typedef struct ListNode ListNode;然后在题目给的函数中实现
typedef struct ListNode ListNode;
struct ListNode* reverseList(struct ListNode* head)
{
ListNode* n1, * n2, * n3;//创建3个变量
n1 = NULL;//给三个变量赋值
n2 = head;
n3 = n2->next;
while (n2)
{
n2->next = n1;
n1 = n2;
n2 = n3;
if(n3) //n3为不空时才继续往后走
n3 = n3->next;;
}
return n1;
}这是链表不为空的情况,那链表为空时呢?直接返回 head 就可以了
typedef struct ListNode ListNode;
struct ListNode* reverseList(struct ListNode* head)
{
if (head == NULL) //空链表
return head;
//非空链表
ListNode* n1, * n2, * n3;//创建3个变量
n1 = NULL;//给三个变量赋值
n2 = head;
n3 = n2->next;
while (n2)
{
n2->next = n1;
n1 = n2;
n2 = n3;
if(n3) //n3为不空时才继续往后走
n3 = n3->next;;
}
return n1;
}题目3:快慢指针
这道题的思路也很多,本篇想通过这题介绍一种很妙的方法,快慢指针,快慢指针在之后的很多题中也有很多应用
先来介绍一下快慢指针,slow表示慢指针,fast表示快指针
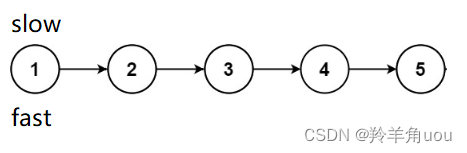
慢指针slow一次往后走一步,快指针fast一次往后走两步
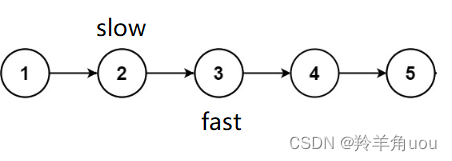
fast没有走到空,继续走,slow一次往后走一步,fast一次往后走两步
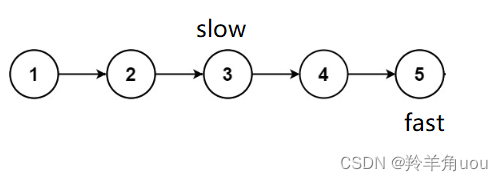
fast不能再继续往后走,此时slow所指向的节点就是链表的中间节点,这是节点个数为奇数的情况如果节点个数为偶数个呢?我们来看看
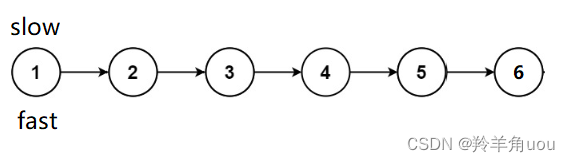
依旧是慢指针slow一次往后走一步,快指针fast一次往后走两步
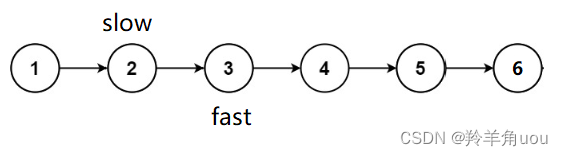
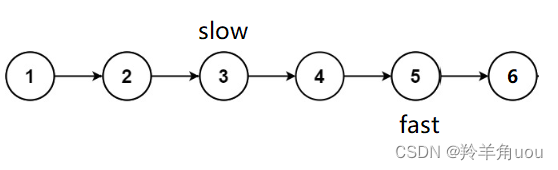
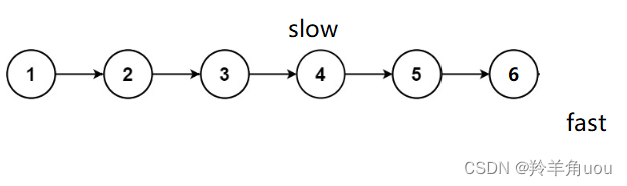
此时fast走到空了,不再继续往后走,slow所指向的节点正是第二个中间节点
这就很简单了,我们将快慢指针运用到题目中,代码实现一下
typedef struct ListNode ListNode;
struct ListNode* middleNode(struct ListNode* head)
{
ListNode* slow, * fast;
slow = fast = head;
while (fast && fast->next)
{
slow = slow->next;
fast = fast->next->next;
}
return slow;
}这里需要注意:while循环里面的判断条件 (fast && fast->next) 中 fast 不能和 fast->next 交换位置,因为如果链表结点个数是偶数个时,fast会走到NULL,当fast走到NULL时,while再对fast->next进行判断,此时可以对空指针解引用吗?不可以。所以fast->next不可以放在前面。当fast放在前面,此时fast为NULL,直接退出循环,根本就不会对后面的表达式进行判断,也就不会出现对空指针解引用的情况。
题目4:哨兵位节点
我们先说没有哨兵位的代码,哨兵位后面再分析
这题我们先选择创建新链表,遍历原链表,我们定义两个指针遍历两个链表
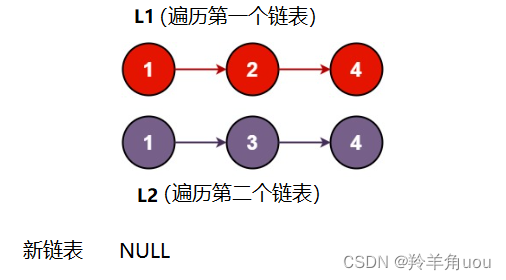
把值小的节点放在新链表中,相等的话随便放哪个都行,然后让相应的指针往后走一个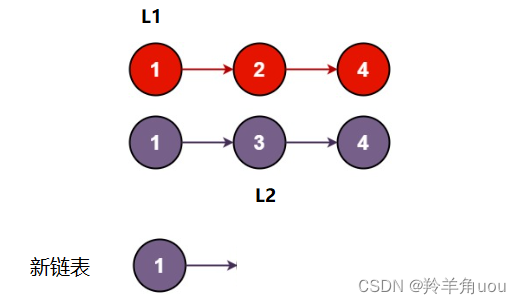
此时L1和L2比较,L1比L2小,把L1的节点放到新节点,然后L1往后移
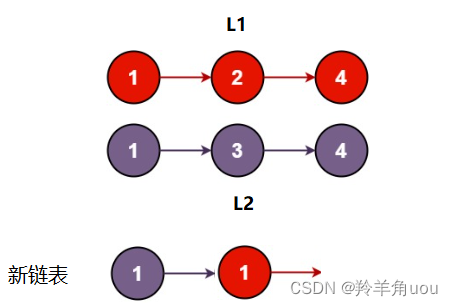
然后再依次向后比较,一直到L1或L2走到NULL为止,遍历结果只有两种情况,要么L1为空,要么L2为空

我们代码实现一下,先写L1的值小于L2的值的时候
typedef struct ListNode ListNode;
struct ListNode* mergeTwoLists(struct ListNode* list1, struct ListNode* list2)
{
ListNode* L1 = list1; //遍历原链表
ListNode* L2 = list2;
ListNode* newhead, * newtail; //创建新链表
newhead = newtail = NULL;
while (L1 && L2)//循环遍历,有一个走到NULL就退出
{
if (L1->val < L2->val)//L1的节点值小
{
if (newhead == NULL) //新链表为空链表
{
newhead = newtail = L1;
}
else //新链表不为空链表
{
newtail->next = L1;//把L1放在新链表
newtail = newtail->next;
}
L1 = L1->next;//L1往后走
}
else //L2的节点值小
{
}
}
}L2小于L1的时候也是类似的,此时while循环内代码为
while (L1 && L2)//循环遍历,有一个走到NULL就退出
{
if (L1->val < L2->val)//L1的节点值小
{
if (newhead == NULL) //新链表为空链表
{
newhead = newtail = L1;
}
else //新链表不为空链表
{
newtail->next = L1; //把L1放在新链表
newtail = newtail->next;
}
L1 = L1->next;//L1往后走
}
else //L2的节点值小
{
if (newhead == NULL) //新链表为空链表
{
newhead = newtail = L2;
}
else //新链表不为空链表
{
newtail->next = L2;//把L2放在新链表
newtail = newtail->next;
}
L2 = L2->next;//L2往后走
}
}跳出循环后有两种情况,要么L1先走到空,要么L2先走到空 ,上面的情况就是L1走到空,L2没有走到空,我们直接把L2拿下来尾插就行了,出while循环后的代码如下
//跳出循环后
if (L2) //L2没走到空
newtail->next = L2;
if (L1) //L1没走到空
newtail->next = L1;
return newhead;我们还需要处理一下空链表的情况,空链表的情况代码放在函数体最前面
//空链表的情况
if (list1 == NULL)
return list2;
if (list2 == NULL)
return list1;我们会发现代码重复的部分很多,我们如何去优化它?首先要找为什么会重复
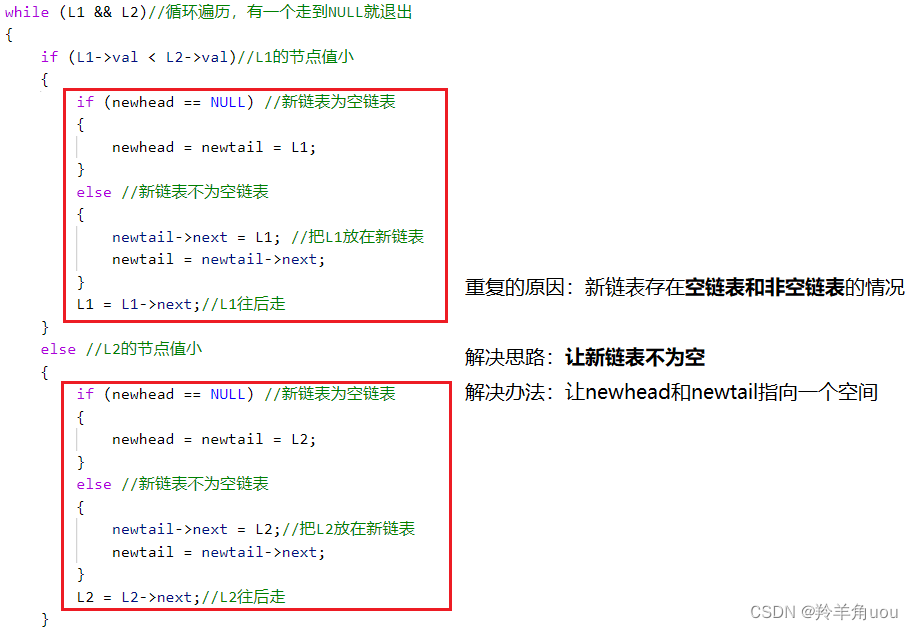
我们向操作系统申请一个空间,这个空间不存有效数据
newhead = newtail = (ListNode*)malloc(sizeof(ListNode));此时链表也改变了


所以现在的代码就变了,返回值也变了
typedef struct ListNode ListNode;
struct ListNode* mergeTwoLists(struct ListNode* list1, struct ListNode* list2)
{
//空链表的情况
if (list1 == NULL)
return list2;
if (list2 == NULL)
return list1;
ListNode* L1 = list1; //遍历原链表
ListNode* L2 = list2;
ListNode* newhead, * newtail; //创建新链表
newhead = newtail = (ListNode*)malloc(sizeof(ListNode));
while (L1 && L2)//循环遍历,有一个走到NULL就退出
{
if (L1->val < L2->val)//L1的节点值小
{
newtail->next = L1; //把L1放在新链表
newtail = newtail->next;
L1 = L1->next;//L1往后走
}
else //L2的节点值小
{
newtail->next = L2;//把L2放在新链表
newtail = newtail->next;
L2 = L2->next;//L2往后走
}
}
//跳出循环后
if (L2) //L2没走到空
newtail->next = L2;
if (L1) //L1没走到空
newtail->next = L1;
return newhead->next;
}我们malloc的空间要记得释放,所以可以在return上面加三排代码,而且return的值也要改一下
ListNode* ret = newhead->next;//存newhead->next的值
free(newhead);
newhead = NULL;
return ret;所以这里的头节点就是哨兵位
题目5:环形链表
我们先介绍一下约瑟夫问题的历史背景
据说著名犹太 历史学家 Josephus( 弗拉维奥·约瑟夫斯 )有过以下的故事:在罗马人占领乔塔帕特后,39 个犹太人与Josephus及他的朋友躲到一个洞中,39个犹太人决定宁愿死也不要被敌人抓到,于是决定了一个自杀方式,41个人排成一个圆圈,由第1个人开始报数,每报数到第3人该人就必须自杀,然后再由下一个重新报数,直到所有人都自杀身亡为止。约瑟夫将自己和他的朋友安排在16和31个位置,于是逃脱了这场死亡游戏
来看一下环形链表
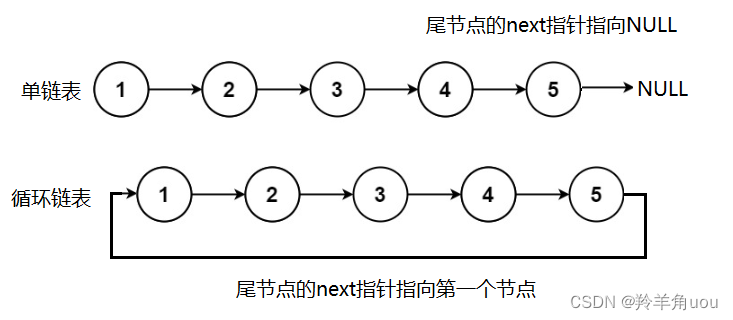
我们画个图简单介绍一下
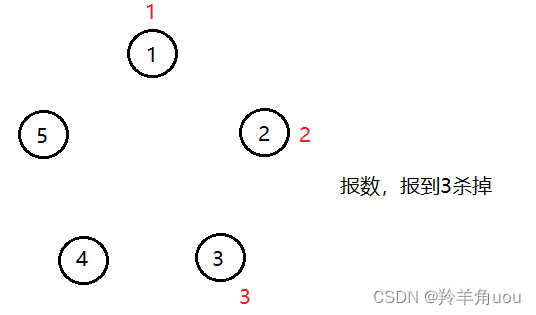
此时把3节点去掉,继续从下一个存在的节点开始报数
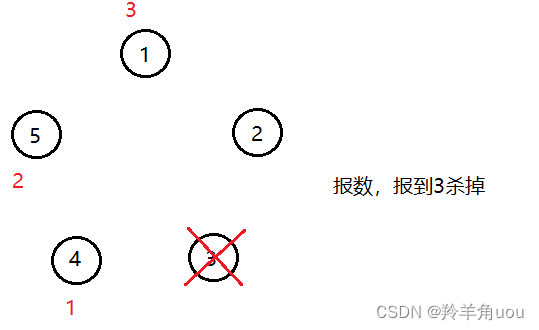
再把节点1去掉,继续从下一个存在的节点开始报数
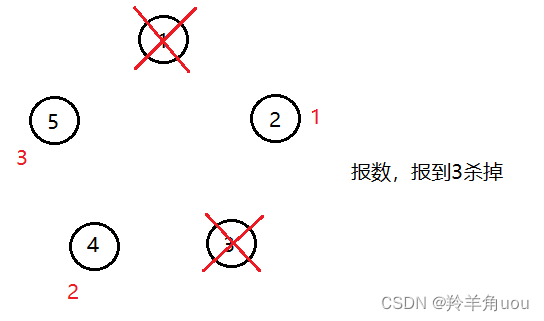
把节点5去掉,现在留下两个节点,如果约瑟夫和他的朋友想要存活,就要站在2或4的位置
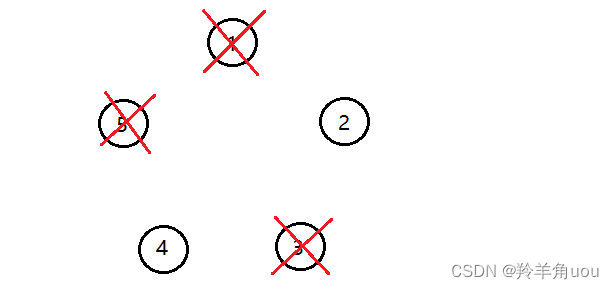
那么这道题就是类似,不过是留下一个节点
拿5个节点,报数为2举例
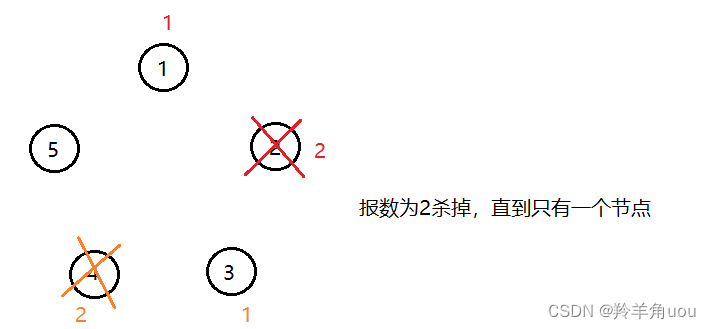
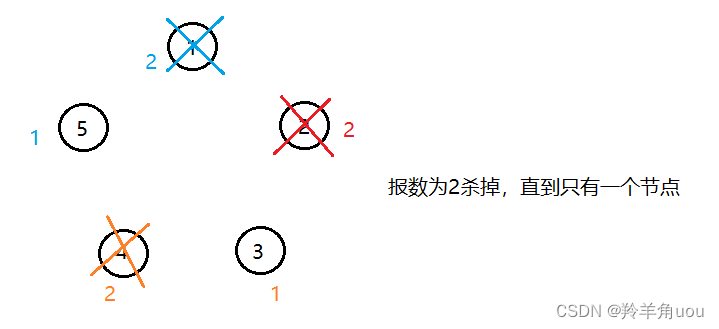
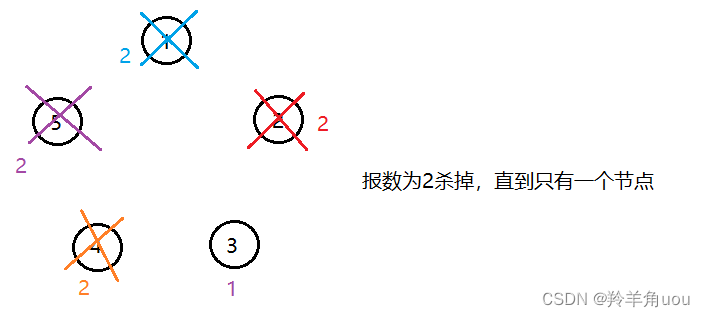
最后就留下了节点3
代码中我们如何分析呢?看下图。

数1之后数2,此时pcur后移,prev后移
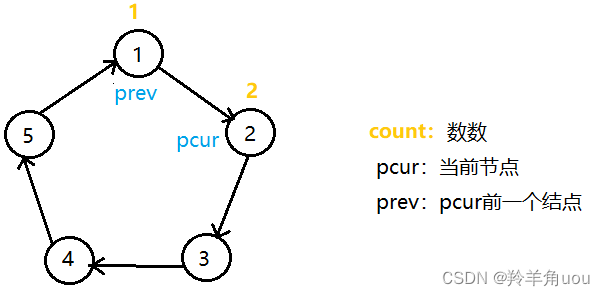
pcur所指向的节点数到了2,要销毁pcur所指的节点,销毁的时候先让prev的next指针指向pcur的next
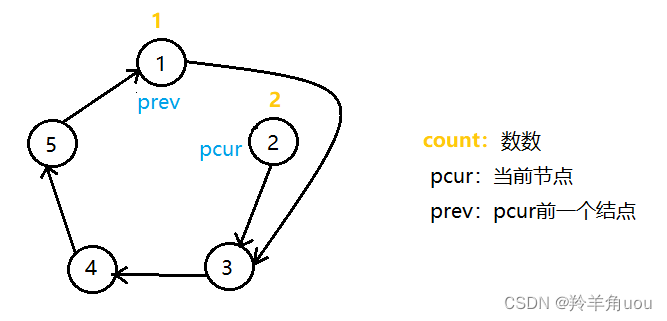
然后把pcur指向的节点销毁,并且让pcur指向下一个节点,也就是prev的next指针指向的位置
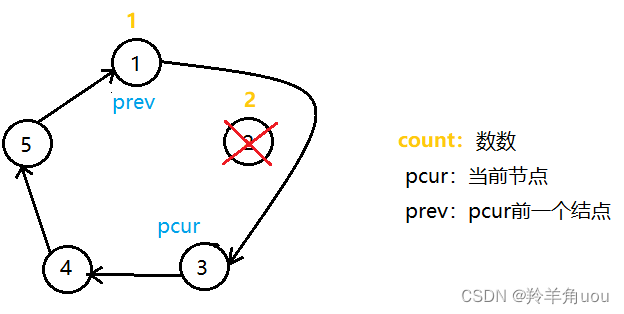
然后继续数数,从1开始
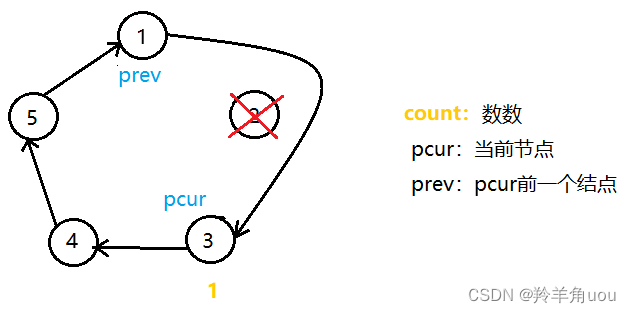
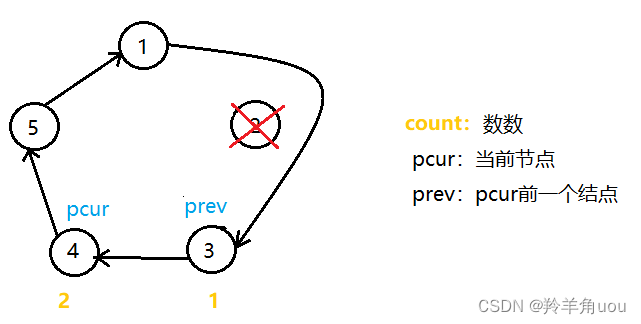
然后就是重复步骤,当只剩下两个节点时,分析一下
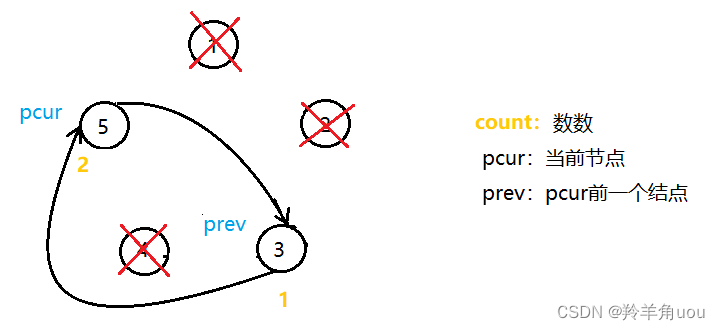
pcur报数为2,删掉5这个节点,要先让prev的next指针指向pcur的next,也就是节点3此时自己指向自己
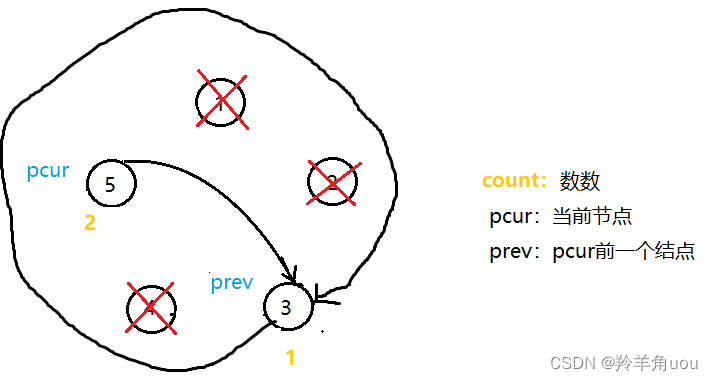
然后再销毁节点5,此时pcur也指向节点3
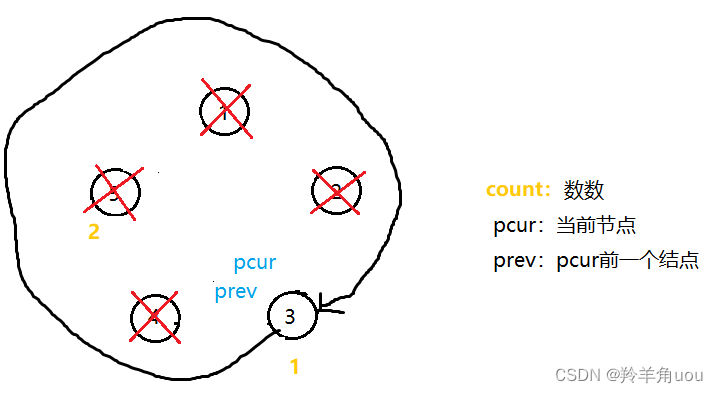 大概分析就是这样,我们代码实现一下
大概分析就是这样,我们代码实现一下
1.先创建带环链表
先写一个创建节点的函数
typedef struct ListNode ListNode;
ListNode* BuyNode(int x)//创建节点
{
ListNode* node=(ListNode*)malloc(sizeof(ListNode));
if(node==NULL)
{
exit(1);
}
node->val = x;
node->next = NULL;
return node;
}然后写带环链表的函数
ListNode* CreatCircle(int n)//创建带环链表
{
ListNode* phead=BuyNode(1);//先创建头节点
ListNode* ptail=phead;
for (int i = 2; i <= n; i++)
{
ptail->next=BuyNode(i);//尾插新节点
ptail = ptail->next;
}
ptail->next=phead;//头尾相连,变成循环链表
return ptail;
}然后在ysf函数中实现
int ysf(int n, int m )
{
ListNode* prev = CreatCircle(n);//环形链表尾节点由prev接收
ListNode* pcur = prev->next;//头节点由pcur接收
int count = 1;
while (pcur->next != pcur)
{
if(count == m) //需要销毁节点
{
prev->next = pcur->next;
free(pcur);
pcur = prev->next;
count = 1;//重新计数
}
else //不用销毁节点
{
prev = pcur;
pcur = pcur->next;
count++;
}
}
return pcur->val;
}这次分享就到这里了,拜拜~



![[Algorithm][滑动窗口][无重复字符的最长字串][最大连续的一个数 Ⅲ][将x减到0的最小操作数]详细讲解](https://img-blog.csdnimg.cn/direct/7016be5433bb474493c02d5333c51969.png)